The scope of the database component of the DEIMOS software complement has been reviewed and revised since the PDR (see part 1, chapter 2, section 5). We currently plan to use the online database for five major instrument support functions:
Implicit in our plans is the continued use of the STB image archiving software at Keck, and the continued ingestion of image headers into the online database there for later search, retrieval, and analysis. These procedures are already in place and do not require DEIMOS resources. We have abandoned any plan to implement a special image archiving facility for DEIMOS.
For full engineering support of the instrument, complete telemetry and logging of instrument and telescope/dome control systems is desirable. However, truly complete telemetry and logging should be provided by a CARA effort (or by a joint effort between CARA and Lick) for support of all instruments at K1 and K2, not by DEIMOS funds. Some discussion has already taken place between CARA and Lick as to a joint effort to improve logging and image archiving. This effort might involve new keywords for CARA systems, and is outside the scope of the DEIMOS project.
Absent the sudden realization of this joint effort, DEIMOS database logging and analysis will be limited to information readily available via current CARA KTL facilities, and its purpose and scope will be limited to instrument engineering and science support. No effort will be made to provide Web-based public access; the focus will be on tools and utilities for CARA and Lick engineers and DEIMOS observers only.
In reviewing our progress to date, it is clear that over 90% of the schema design for DEIMOS is already complete, and that the suite of documentation generators is at least 80% complete. The keyword dictionary is over 90of Agents and high level system designs are already expressed in database form. Most remaining incomplete or uncommenced modules are relatively simple extract generators, with the exception of EngDataVisu (q.v.). and CodeGen.
In other words, a large percentage (definitely more than 75of the effort of DEIMOS database development has already been realized in the course of preparation for the CDR. The remaining problems are not schema problems, but extract problems; and only two of those are likely to be nontrivial. We feel that this is good news. We are also pleased with the benefits realized so far from the ``authoritative database" approach, particularly in the generation of figures and reference sections for this CDR report and the LOTR. In sum, we find our results so far quite encouraging, and do not see grounds for concern that the database component per se will delay the project schedule or consume more than its share of resources. So far it appears to be ahead of other major instrument subsystems, and to be cost-effective.
Having limited and defined the scope of the database component to five areas, we now present an overview of each one.
At the core of the DEIMOS information management system is a database schema representing (among other things) KTL/FITS keywords. This schema represents not only the simple attributes of keywords (such as datatype, read/write-ability, and format) but complex relationships between keywords (such as that NAXIS controls the instantiation of CRVALn), and conditions of identity and variance among keywords with the same names. In addition to describing keywords as they appear in FITS headers, the schema also represents the mapping of internal instrument control system values into external representations (using simple lookup table maps or more complicated mathematical transforms).
From the tables comprising this schema, various forms of documentation can be generated. We can produce HTML or LaTeX formal documentation for keywords (a ``dictionary" of DEIMOS keywords generated in this fashion is found in the Lick Observatory Technical Report (LOTR) accompanying the CDR document). It is not difficult to add other markup languages such as SGML or MIF (Maker Interchange Format) as long as they support constructs similar to those in LaTeX and HTML.
We can produce fake FITS headers (to test data reduction or other image-handling software). Some additional documentation products will be discussed below. We can also generate certain repetitive blocks of low-level source code for the instrument control system. Related tools can convert ``bundles" of keywords into SQL code that creates appropriate database table definitions for the storage of those keywords (thus, a FITS header definition can be transformed automatically into a database table).
Not only FITS/KTL keywords (and hierarchical collections of those keywords) can be documented in this fashion. All the database tables required for the DEIMOS project are also defined in the ``keyword" schema. Since the schema has taken on a more general function than the description of literal keywords, it's no longer called the Keywords database, but has acquired the nickname ``Memes" (a database of units of meaning). The database table definitions in the Memes database can be documented formally using the same utilities that produce keyword documents, and we have tools to convert an existing Sybase table automatically into a bundle of Memes requiring only minimal further data entry for full documentation. Features such as primary and foreign keying are easily represented in the schema and expressed in the documentation, and SQL code for table creation is (as mentioned above) easily generated from the schema. See Figure 7.8 for a high-level picture of the Memes tables.
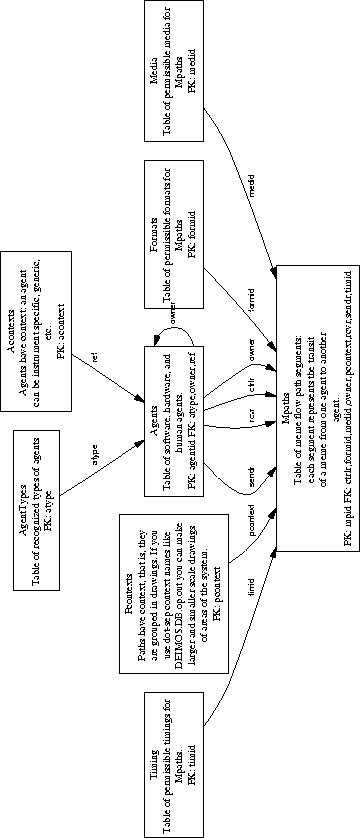
An additional schema representing DEIMOS system components (software, hardware, and human ``agents") permits us to describe the migration of memes (information) through the instrument, or through the observing (or slitmask fabrication, or calibration...) process. Diagrams showing the collection, generation, modification, and movement of information by and between agents document the software/hardware design of the instrument and the observing process. This additional schema, the ``MFlow" schema (when fully populated), should describe and document, at both a high level of generality and a low level of minute detail, the intent and design of our finished products.
The MFlow schema is a cluster of tables documenting Agents (software or otherwise) and the Formats and Media in which information travels among them. A table of Timings expresses the scheduling of information transit (On Demand, Cron Job, End of Exposure, etc.). A table of Mpaths (Meme Paths) describes the passage of information (Memes) between agents. Several figures in this chapter are generated from the data stored in this schema. See Figure 7.9 for a high-level picture of the MFlow tables.
A relatively simple sketching tool (``Etcha") is used to draw initial designs, which can then be committed to the database, recalled, revised, and so forth. A report generator (tracepaths) is used to produce ``dot language" files for input to a digraph generation tool (dot), which produces camera-ready PostScript output. See Figure 7.4 for a typical Etcha session.
More detailed information about Etcha and related tools will be found in Part I, Chapter 3 (Proofs of Concept) Section 3 (System Design Tools). Exhaustive definitions of the Memes and MFlow schemata will be found in the accompanying Lick Observatory Technical Report.
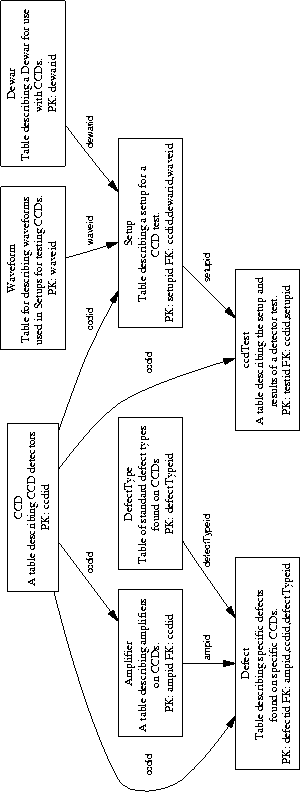
In addition to such abstract entities as keywords, software modules, etc., the instrument also possesses simple, physical components like filters, gratings, and detectors. See Figures 7.10 and 7.11 for a high-level picture of the tables describing physical components of the instrument. These provide a portion of the ``as-built" documentation describing DEIMOS in its finished (commissioned) state.
The entire ``knowledge base" about DEIMOS that resides in the online
database, most of which will be accessible to the DEIMOS user at all times during
observing ![]() . From overview to fine detail, we plan to make the complete
information set available for the benefit of observers, OAs, and Lick/CARA
engineers onsite. For example, one optional attribute of some KTL keywords
is a signal ID (on the electronics drawings) and the test point or pinout
at which the signal can be tested. In the online DEIMOS documentation
system, this information can be looked up rapidly and interactively
by keyword name. It also appears (where available) in the LOTR.
. From overview to fine detail, we plan to make the complete
information set available for the benefit of observers, OAs, and Lick/CARA
engineers onsite. For example, one optional attribute of some KTL keywords
is a signal ID (on the electronics drawings) and the test point or pinout
at which the signal can be tested. In the online DEIMOS documentation
system, this information can be looked up rapidly and interactively
by keyword name. It also appears (where available) in the LOTR.
The GUI Builder (``Dashboard") merits mention in this section because of its ability to use the Memes database to configure its behaviour. It can be made to cache the retrieved information in ASCII files, and can thereafter be started and run with no further online database access; however, its design is based on the notion of an available, authoritative database of keyword specifications. More detailed information about Dashboard and related issues will be found in Part I, Chapter 3 (Proofs of Concept) Section 2 (GUI Builder).
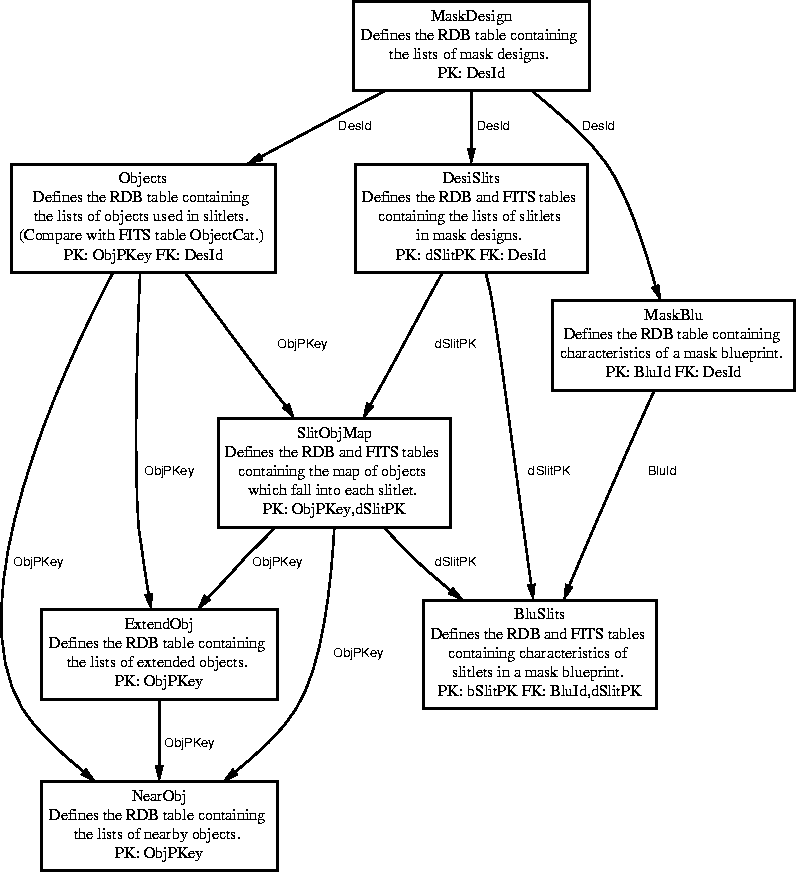
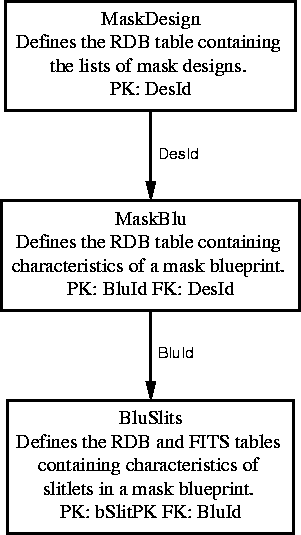
The fabrication and use of DEIMOS slitmasks requires a lot of record-keeping (like any industrial fabrication process) to ensure quality control and appropriate deployment of finished masks. There will be hundreds of DEIMOS slitmasks, with operational lifetimes of anywhere from part of one night to several weeks or months, all of which must be properly identifiable (by electronic means) throughout their existence. When a mask is damaged or destroyed, the termination of its existence should also be recorded for posterity.
We plan to use the database to store the object catalogs and slitmask blueprints of successfully machined masks. See Chapter 1 (Slit Masks) for a complete description of the mask fabrication process including database interactions.
Masks will be identified by barcode scanning when loaded in the cassette. The complete description of each identified mask, down to the object catalog and milling instructions, can be retrieved at any time. More obviously useful information - such as the observer's nickname for the mask, date of manufacture, and so forth - should help to prevent any confusion, misloading or misidentification of masks (such as has already cost several hours of LRIS time).
See Figure 7.12 and 7.13 for a high-level picture the tables which describe slitmasks.
More detail on the use of database-resident parametric logging as an engineering resource will be found in Chapter 8, Section 3. If detailed parametric logs are available online in database form, analysis and visualization can be made relatively easy. Arbitrary queries across a large dataset are more easily achieved using SQL, or preferably a GUI SQL generator, than by the laborious construction of individual C code modules, FORTRAN programs, awk/sed scripts, or other ``from scratch" approaches.
We propose to perform as complete parametric (environmental) logging as can be achieved at low cost and without undue impact on CARA systems and staff. Our belief is that both software and hardware instrument support will be improved and made easier thereby.
DEIMOS is a complex instrument, and analysis of DEIMOS images will be a complex and time-consuming task if performed by traditional, manual means. We would like to provide some degree of automated or semi-automated (pipeline) data reduction support, or at the very least a useful online library of calibration information for use in manual reduction.
For pipeline data reduction, the database is useful as
a quick method of retrieval for appropriate comparison images and spectra
![]() ,
and for the storage of authoritative information about DEIMOS lamps,
gratings, filters, etc. A body of ``standard calibration data" is
required for pipeline reduction to work, and the retrieval of appropriate
data will be faster and easier using a database. A sketch of this
process will be found in Figure
,
and for the storage of authoritative information about DEIMOS lamps,
gratings, filters, etc. A body of ``standard calibration data" is
required for pipeline reduction to work, and the retrieval of appropriate
data will be faster and easier using a database. A sketch of this
process will be found in Figure ![]() .
Obviously it would be impractical to acquire the mass of calibration data
by any manual process. It should be ingested automatically as the final
step in a successful recalibration procedure (the proposed stable
calibration database and pipeline reduction would require recalibration
to be performed on a regular schedule).
.
Obviously it would be impractical to acquire the mass of calibration data
by any manual process. It should be ingested automatically as the final
step in a successful recalibration procedure (the proposed stable
calibration database and pipeline reduction would require recalibration
to be performed on a regular schedule).
We have proposed to store, in addition, more abstract entities like coefficients for interpolation and correction algorithms. (see the Lick Observatory Technical Report number XX documenting the database schema and DEIMOS keywords). See Part III for details of the calibration and pipeline data reduction proposal, associated procedures, and the role of the database in facilitating calibration and pipeline reduction.
Instrument stability is an unknown quantity at the time of writing, as are many details of flexure correction and calibration requirements. All schema and procedures related to these topics should be regarded as parts of an experimental model, almost certain to change significantly before commissioning. The data reduction pipeline, though useful, is not absolutely necessary at commissioning, and will not be delivered if time and budget constraints bring it into conflict with other more essential deliverables.
Having defined the role of the online database with greater precision than we could at the PDR, we are able to document existing (production) schema currently in use (Memes, MFlow), well-developed schema soon to be implemented for instrument assembly and testing (Optical components, Slitmasks), and speculative schema (FCS, Calibration) for processes and techniques not yet fully understood. We can also define fairly accurately the list of software modules needed to make use of the information stored in these schemata, and their functions (again, some are already in production and others are only in design or early prototype).
The remainder of this chapter consists of Figures, a Glossary, Software Module descriptions, Procedure Descriptions, a list of major deliverable documentation products, and Schema Documentation.
In reading the information flow diagrams in this and other chapters you may find the following translations helpful.
Figure 7.1: Operational Role of the Database
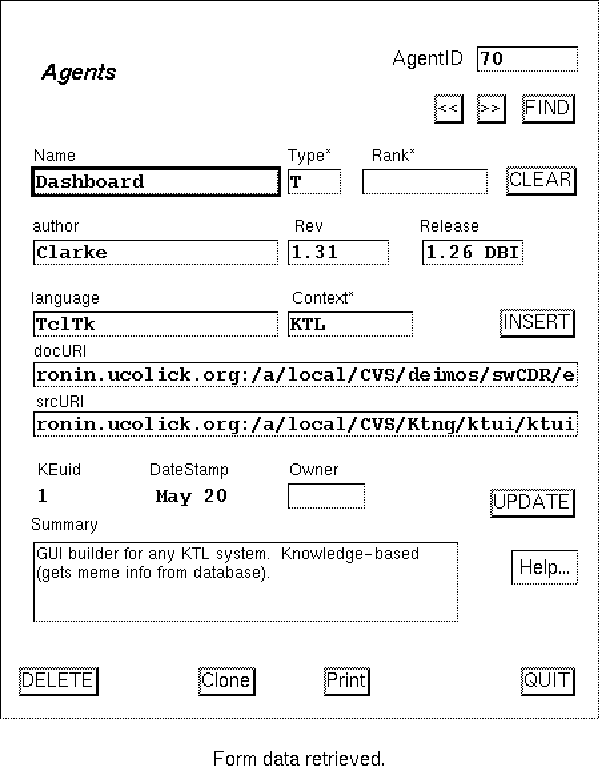
Figure 7.2: Typical Data Entry Form: Memes
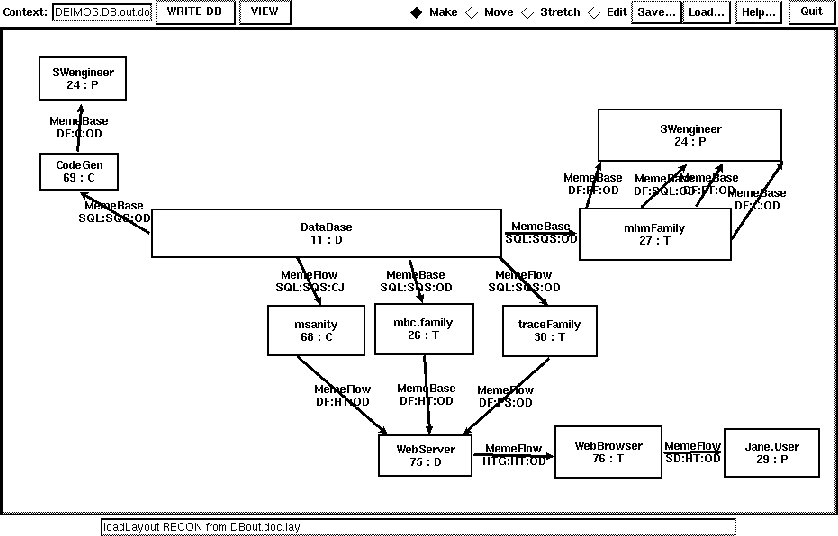
Figure 7.3: Typical Data Entry Form: Agents
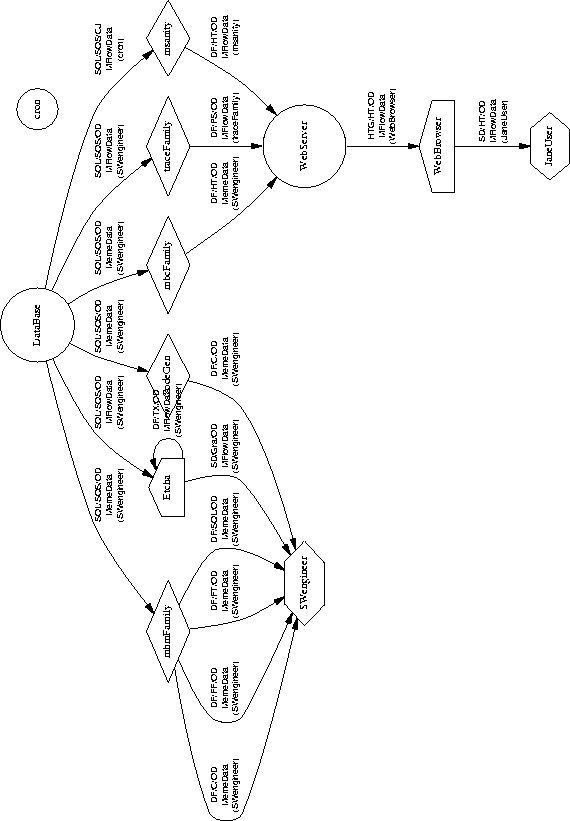
Figure 7.4: Typical Etcha Screen: DEIMOS.DB.out.doc
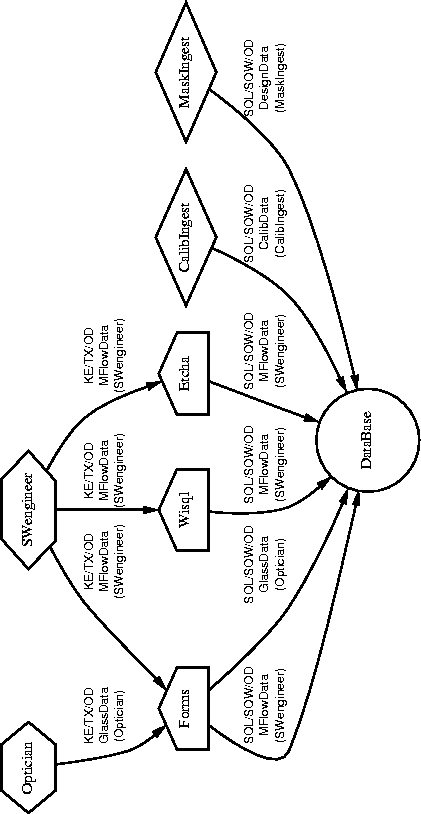
Figure 7.5: Finished Drawing: Database Documentary Outputs
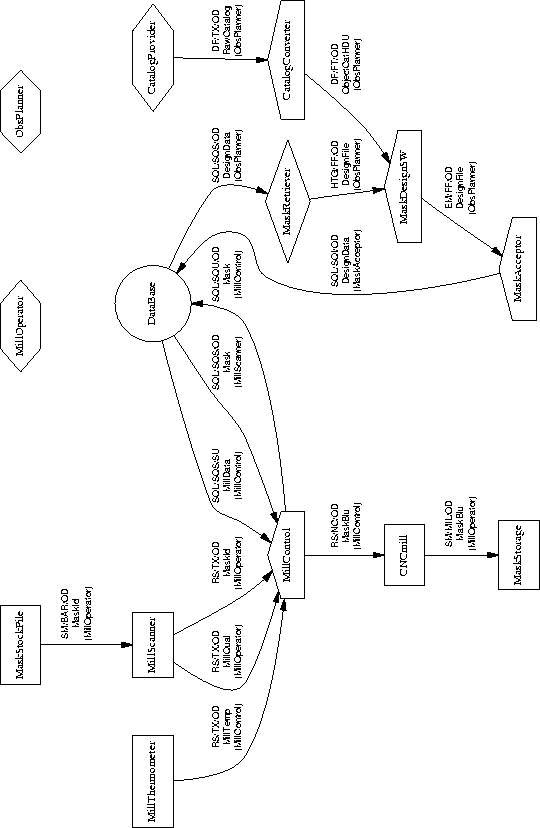
Figure 7.6: Finished Drawing: Database Information Inputs
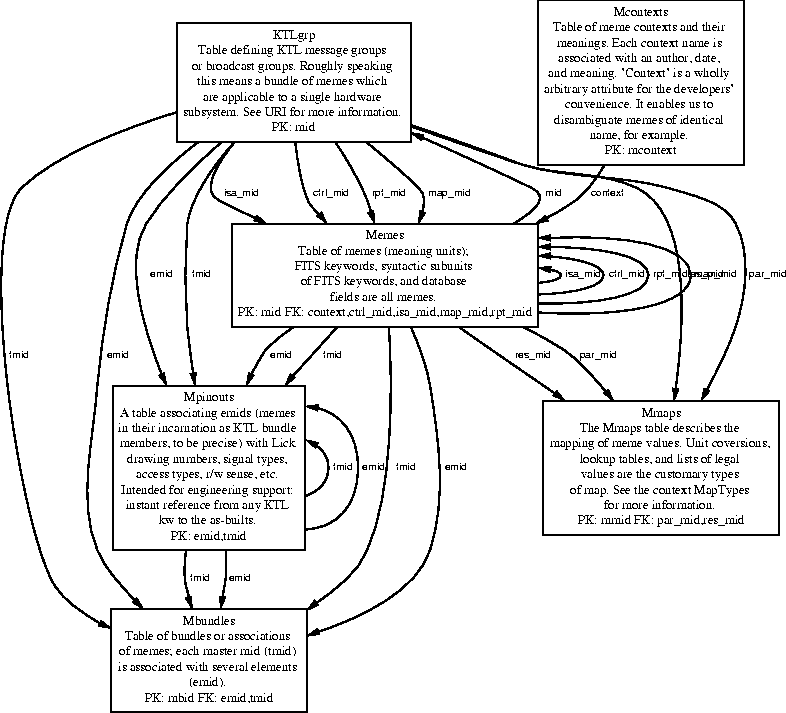
Figure 7.7: Finished Drawing: Slit Mask Production
The heart of a KTL-based instrument is keywords, so the central fact of software design for such an instrument is inventing keywords and deciding (collectively) on their nomenclature, meaning, and usage. These decisions are formalized by data entry in the Memes schema. The software engineers enter data directly into tables using the Forms interface (see Figure 7.2) to create and correct information about keywords. They use utilities like mbc and mhm (directly or via a Web page) to check their data entry, or inspect the results of msanity online using a Web browser. The feedback loop is rapid; corrections and changes are easily made.
When the keyword database is correct, formal documentation is generated by means of Makefiles which produce LaTeX (stage 1) then produce HTML from the LaTeX source.
Software engineers use Etcha to sketch functional diagrams and to create new Agents (they can also use Forms to create Agents). They subsequently commit those diagrams to the database, then view the resulting PostScript drawing and correct the sketch as needed. The feedback loop, again, is rapid. Utilities like tracepaths and traceagent can also be used manually to verify the data, detect errors, and answer such questions as ``What are the implications of changing Agent X?" Designs can be revised (and should be revised) at any time, before or after commissioning, since 90% of the documentation can be regenerated automatically.
The nature of these procedures is interactive. People browse and edit data interactively, then run ``batch" jobs to process the data into useful output. A cronned script could regenerate online user documentation every N hours after commissioning, to ensure that online information was fresh and correct.
We anticipate that user interaction with the documentary information will also be interactive, via Web pages and dedicated small GUI integrated with the rest of the DEIMOS software.
We speculate that instrument recalibration should be done on a regular schedule by CARA staff after commissioning. We speculate further that this procedure should be semi-automated by means of scripts. The scripts should produce some datafiles which are then automatically imported into the database when the instrument specialist is happy with the calibration. These calibration data will be used later for observing and data reduction.
The nature of this procedure is semi-interactive. The instrument specialist interacts with scripts and possibly a simple GUI, but the data capture, assembly, and import is done invisibly and automatically.
The nature of pipeline reduction is semi-interactive. The observer interacts with a simple GUI to establish general parameters; the GUI retrieves appropriate calibration data for the image to be processed, and generates a configuration file to be read by the actual pipeline reduction program. The exact format and content of these configuration files is still under discussion, but they will almost certainly be FITS table extensions such as we already know how to produce automatically from the database.
This topic is covered in detail in Chapter 1. In brief: slit mask designs are requested by mailing (or otherwise conveying) a standard Design/Blueprint File to the Observatory. This file is ingested into the database. The Mill Operator's GUI constructs a list of milling tasks from the database of pending Design Files, assigning priority according the ``need dates" supplied by the observer. It then assists the operator through the process of selecting masks to be milled, generating mill control language, and milling. Acceptable masks are ``scanned in" during quality control inspection, which causes the mill date, mask blueprint, the fact of successful milling, etc. to be recorded in the database. The barcode label on the milled blank will from now on be associated with the complete design and specification for that mask. This procedure is semi-automated, requiring no manual user interaction to load or retrieve data.
Recognition of masks at observing time is fully automated. Once the cassette is loaded, it can be scanned under software control and all data for all loaded masks can be automatically retrieved.
Chapter 8 (Alarms and Logging) discusses DEIMOS needs for both event and parametric logging. The procedures for capturing log data should be fully automated. Event logs are usually the record of alarms and other conditions of which the user is notified in real time; they may also be statistically analyzed for frequency of event types, etc. and therefore may be captured in the form of database tables.
However, the data more likely to be intensively analyzed and visualized by engineers and support staff are the mass of parametric log records. Procedures for capturing these data are trivial (monitoring KTL keyword values).
Procedures for analyzing captured parametric data, however, are not so trivial. They should be both interactive (exploratory visualization and analysis) and automatic (routine scans for known phenomena). Routine scans should generate email and/or update Web pages to inform observers and engineers of their results.
The UI should facilitate statistical queries by intuitive time periods and provide quick and useful graphical representations of results. Here the rapid retrieval and flexible query capability of the online database are essential in crafting a user interface fast and easy enough to encourage effective use of the data.
Besides the need for occasional updates or corrections to keyword and design information, there will be need for certain basic maintenance activities on growing data stores (like the parametric log table(s)). Reindexing of rapidly-growing tables is necessary to preserve performance, and eventually (over a period of two or more years) log tables may grow beyond the bounds of real utility. Re-indexing can almost certainly performed by a cron job, but data pruning is a more critical operation and should probably be performed (at long intervals) by a CARA or Lick staff person. All automated data maintenance tasks must send confirming mail and log their activities, to ensure that staff are made aware of their success or failure.
Procedures which must be performed only at long intervals are easily forgotten; some automatic reminder mechanism will be needed to alert staff when such procedures are needed. Warnings and reminders should be issued well in advance of any actual failure date, so that staff have adequate time for scheduling these tasks.
Another procedure that cannot effectively be automated is the update of the Memes database to reflect the appearance of new keywords or changes to the usage of existing keywords. One or two instrument specialists, programmers, or engineers will need, over a period of months or years, to update the Memes database occasionally when keywords or reference tables change. Synchronization of the Santa Cruz and Waimea copies of the database is a serious concern, but one which I feel can be solved using existing resources.
The data maintenance procedure which represents real costs in staff time is the proposed Instrument Recalibration, requiring several hours of instrument time and of an instrument scientists' time as well. The database ingestion phase of this procedure is not the cause of its lengthiness (the length is driven by the minimum useful ELAPTIME and the number of exposures needed to calibrate); and the ingestion itself should be automatic once the actual calibration procedure has succeeded. The capture and maintenance of these calibration data may be the most complicated of all database interfaces for DEIMOS, but we reserve the option not to deliver a data reduction pipeline and therefore to postpone all modules associated with it, including the tools for instrument recalibration.
Most of the documentation to be delivered with the database component of DEIMOS is in the form of data resident in the database. Documentation products that should be delivered at commissioning are:
The complete database schema documentation (detailed information on every table) is to be found in the LOTR. These figures, in conjunction with section 7.1, provides an overview of the schema and its function which may be helpful in understanding the minutely detailed material in the LOTR.
The schema is divided conceptually into subschemata, for ease of comprehension and reference. Here we present EER drawings of the subschemata, to show the number of tables and their general function and relation to one another. The semantics and other attributes of each field will be found in the LOTR, indexed by field name and by table name.
In these drawings, only key fields are explicitly referenced. The notation PK indicates the primary keying of the table, while FK indicates the foreign keying. Arrows are drawn in the traditional EER ``one-to-many" orientation, with the arrowhead on the ``many" side of the relationship. Nuances such as one-to-one and many-to-many are not expressed at this revision of the EER generator.
All of these tables function both as documentary sources (for the generation of online or paper documentation product) and as online references for automated, semi-automated, or user-driven procedures. The information flow diagrams earlier in this chapter show output from the database being used by various agents. Where the general meme names ``mumbleData" have been used, this indicates use of various information from the corresponding schema.
The drawings which follow are another product of the Memes database, which is self-referential and self-documenting.
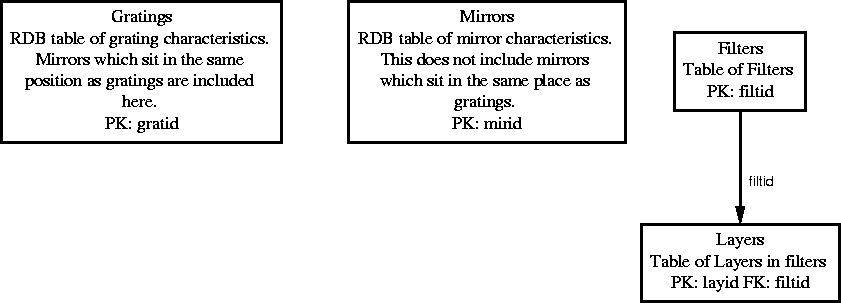
Figure 7.9: Information Flow EER
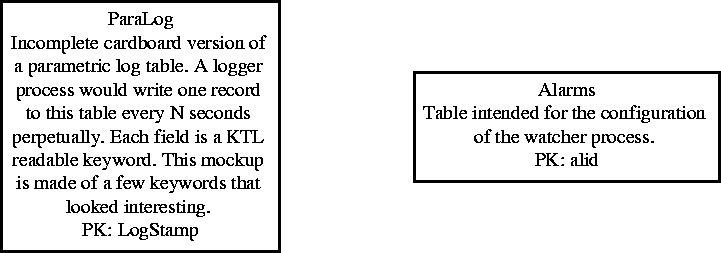
Figure 7.13: Mask Fabrication EER
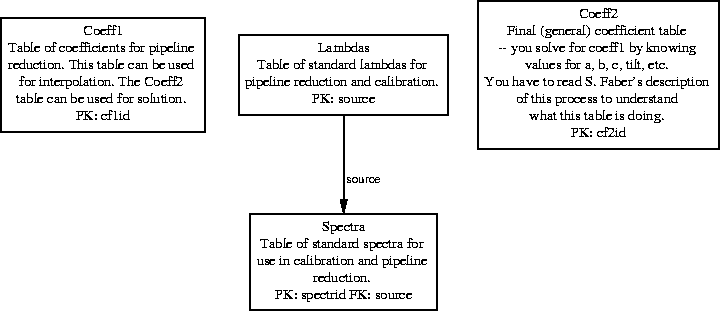
Figure 7.14: Operational Schema EER
![]()
Figure 7.15: Calibration Schema EER